Introduction
Creating websites is a difficult task that requires expertise and a significant amount of time. In a typical web development workflow, web developers implement HTML/CSS and Javascript code based on a mock-up UI, which are created using applications such as Sketch. A task of synthesising HTML/CSS programs from mock-up UIs helps speed up the development process by allowing developers to focus more on implementing Javascript logic.
In this post, we discuss our approaches to address the above problem, which is formally described as follows. Given a set of HTML tags \(\mathcal{T}\), classes \(\mathcal{C}\) of CSS libraries, and a screenshot \(I\) of a target mock-up UI, we generate a HTML program \(P\) that renders \(I\).
We experiment with two different approaches: supervised and reinforcement learning (RL). In the reinforcement learning approach, we aim to learn a Deep Q-network to synthesis HTML program without labelled data. Because the problem space in RL is enormous and we have limited resources, we have not successfully made RL work. The details of our RL approach is described in the Appendix. In the supervised approach, we use CNN to encode the target image \(I\) and LSTM to decode the HTML program \(P\) from \(I\). In our empirical evaluation, it outperforms the current state-of-the-art (pix2code) significantly by 19.7% in term of accuracy.
The most relevant work to this problem is pix2code [1], which also synthesizes HTML programs from images. Besides the difference between neural network architectures, their approach first generates domain specific language (DSL) programs and then, translate DSL programs to final HTML programs. Using DSL makes this problem easier because the lengths of programs are smaller. However, creating DSL may take lots of time, and we may need to develop different DSLs or DSL-to-HTML converters for different CSS libraries. By directly generating HTML/CSS program, our approach is more natural to adapt to various CSS libraries and can access a tremendous amount of publicly available training data in open source projects and websites.
In the remaining parts, we will describe different supervised models and their performances compared to the current state-of-the-art.
Generating HTML/CSS Code with Neural-Guided Search
Similar to XML, an HTML program consists of a sequence of HTML tags, each tag can be an open tag or a close tag (e.g., <h5> and </h5>). In addition, open tags may contain other special attributes such as class to indicate classes they belong to (e.g., <div class="row">). In our system, we represent an HTML program as a sequence of tokens; each token is either an open tag, a close tag, an open tag and its classes, or one of three special tokens: #text, <program>, </program>. The #text token acts as a placeholder for text elements in the mock-up UI. <program> and </program> indicate the beginning and ending of the HTML program, respectively.
Let \(f\) be a function that predicts probabilities of the next tokens \(x_{t+1}\) of the program given a current sequence of tokens \(X_t\) and a target image \(I\). Then, the desired program \(P\) can be generated by repeatedly applying \(f\) in the beam search algorithm to generate one token by one token, and optionally invoke a web rendering program to evaluate and prune search branches until we find the </program> token.
To estimate \(f\), we train a deep learning model that uses CNN to learn a representation vector \(z\) of a target image, then inputs \(z\) with current tokens \(X_t\) of the program to an LSTM to predict the next token \(x_{t+1}\). We experiment with three different architectures; each has different ways of usages of \(z\) and \(X_t\), as follows:
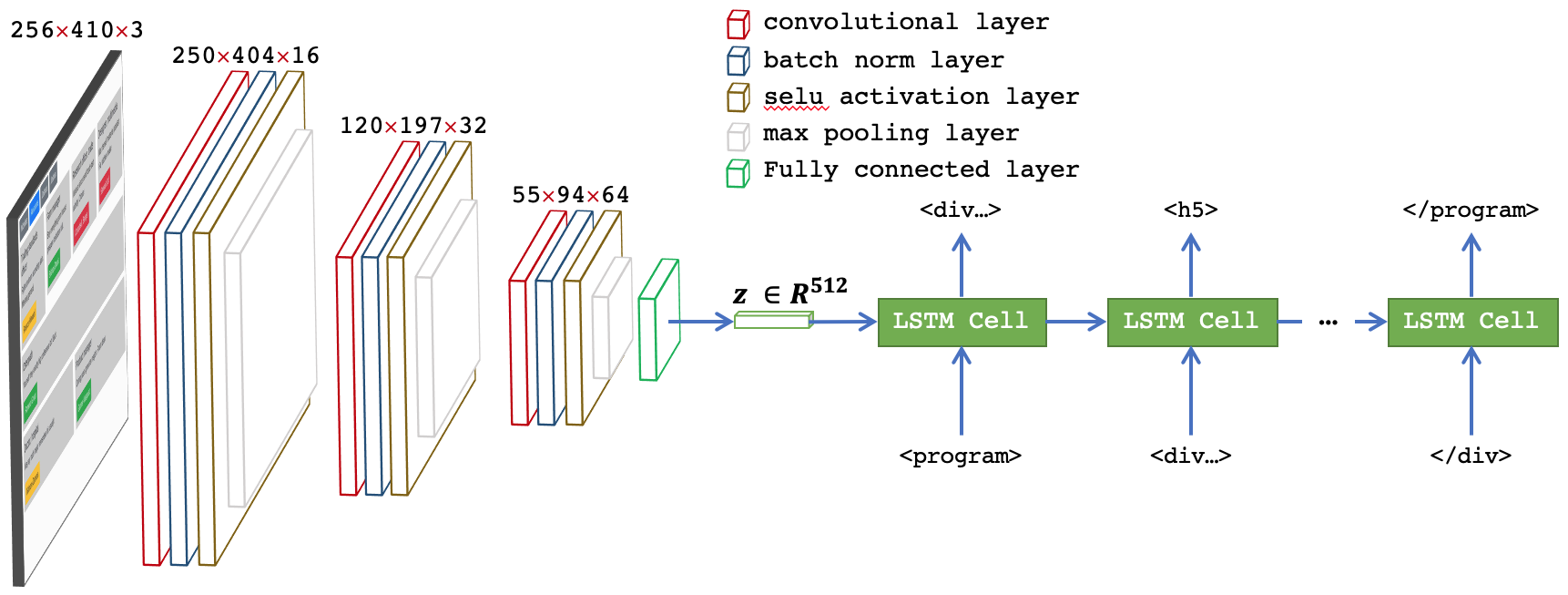
- Using \(z\) as the initial hidden state of LSTM: the architecture of this model (ED-1) is showed in the following figure. It contains three CNN layers extracting features from an image, then passes through a fully connected layer to extract a representation vector \(z\) of size 512. \(z\) is used as the hidden state of a one-layer LSTM (the hidden states are vectors of \(R^{512}\)). LSTM is trained to predict the next tokens of target HTML programs.
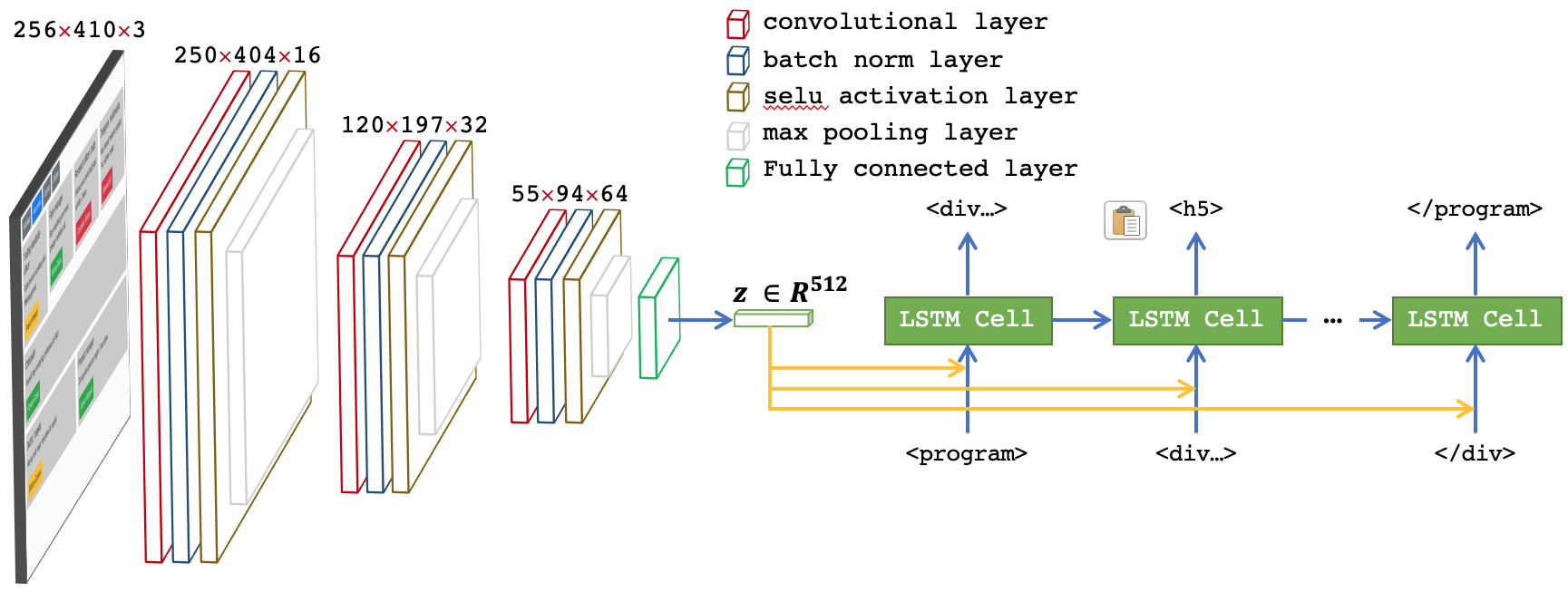
- Concatenating \(z\) with each \(x_{t' \le t} \in X_t\): the architecture of this model (ED-2) is similar to the above model (figure below). However, instead of using \(z\) as the initial hidden state, \(z\) is concatenate with vectors of tokens \(X_t\) and is inputted to the LSTM.
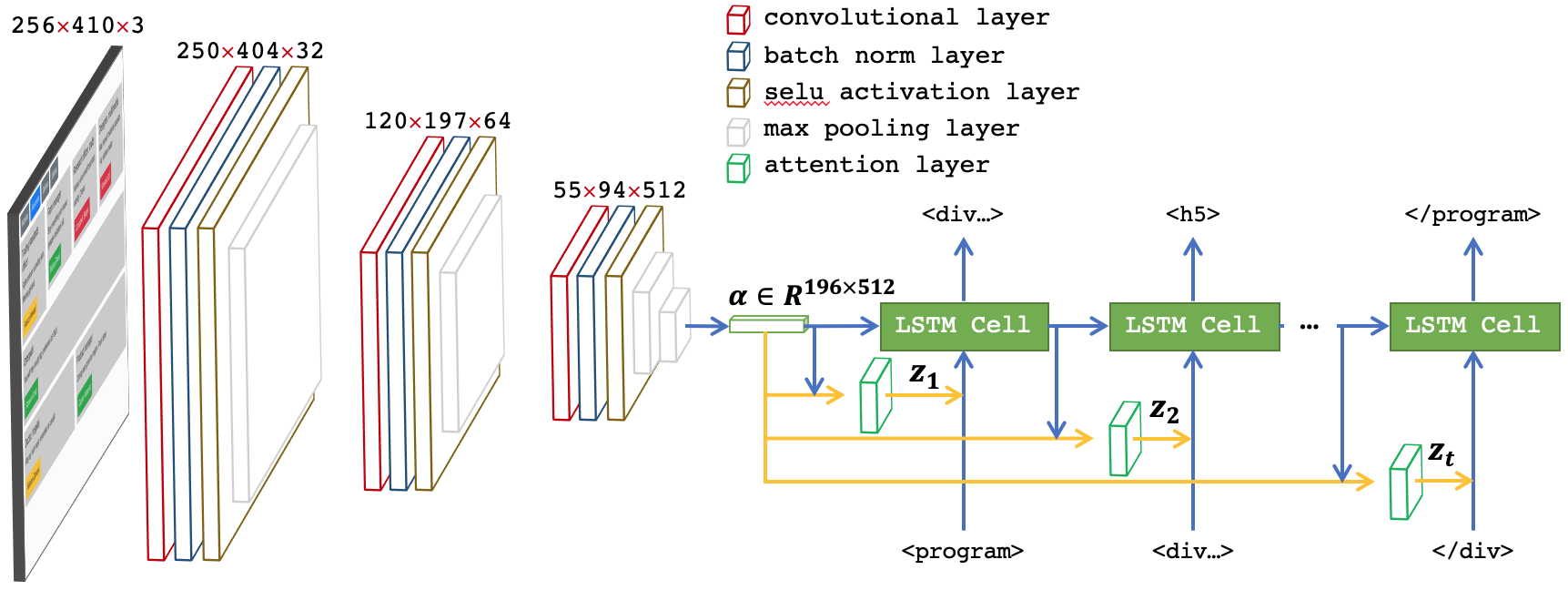
- \(z\) is computed dynamically at each time step \(t\) using an attention layer, and is concatenated with the input token \(x_{t'}\) to predict next token \(x_{t'+1}\): the architecture of this model (ED-3) is similar to ED-2. However, instead of calculating representation vectors \(z\) using a fully connected layer, we compute \(z\) at time step \(t'\) based on the hidden state \(h_{t'}\) and the extracted features vector \(\alpha\) using soft attention mechanism as in Xu et al. [2].
Experimental Evaluation
Dataset and evaluation metric
We evaluate our approach on the synthesized web dataset from pix2code [1]. The details of the dataset are described in the table below. Note that we converted the programs in the original dataset, which are written in DSL to HTML code. Because of that, the average length of the new programs is almost twice as long as that of the original programs.
| Datasets | training | validation | testing | average length of programs |
|---|---|---|---|---|
| pix2code | 1250 | 250. | 250. | 105 |
We assess the quality of predicted programs by comparing with gold programs in term of accuracy as in pix2code [1].
\[\text{accuracy(gp, pp)} = \frac{\sum_{i=0}^{min(|\text{gp}|, |\text{pp}|)} \text{gp}[i] = \text{pp}[i]}{max(|\text{gp}|, |\text{pp}|)}\]where \(\text{gp}\) and \(\text{pp}\) are the predicted program and gold program, respectively, and \(\text{gp}[i]\) is a token at position \(i\) of the program.
Training supervised models
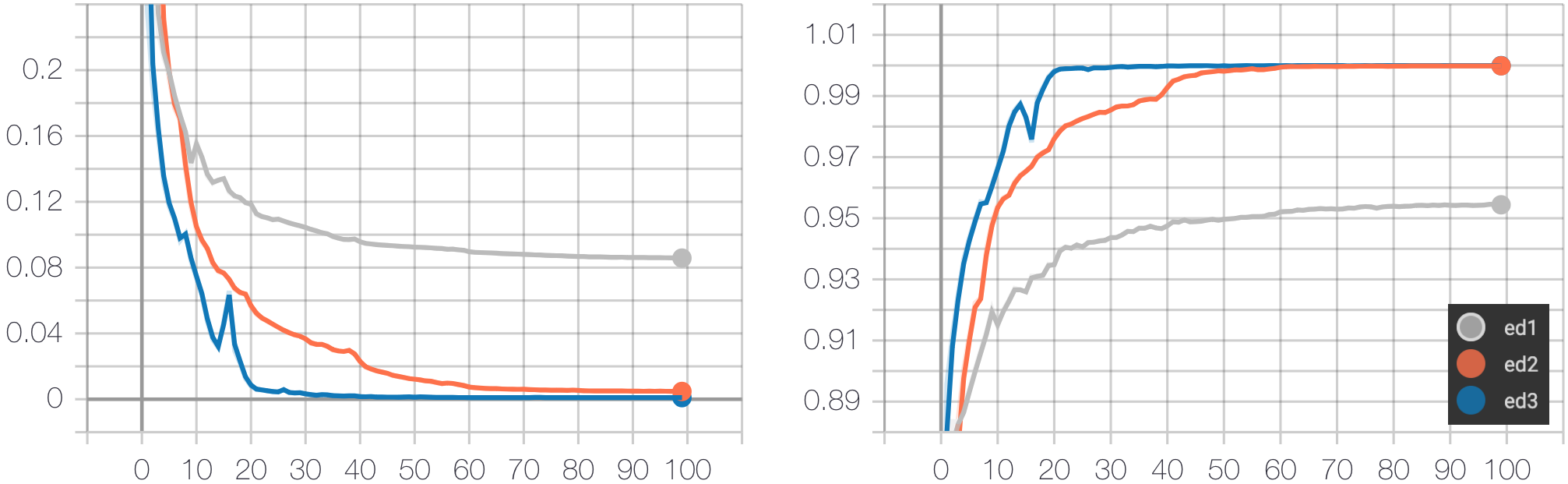
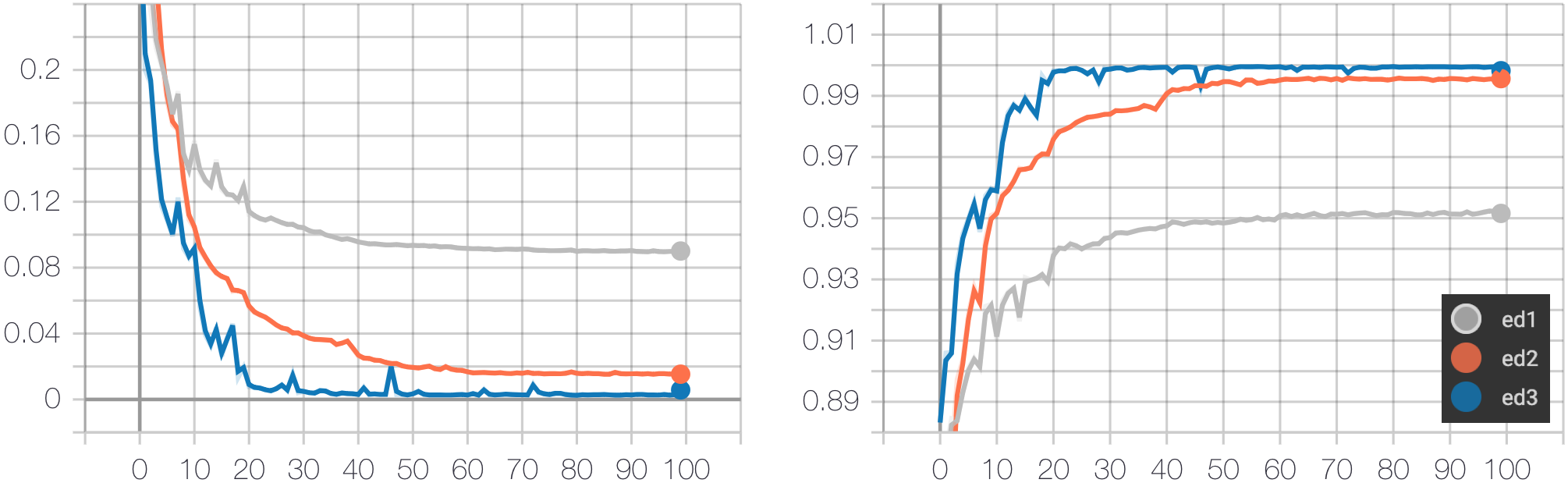
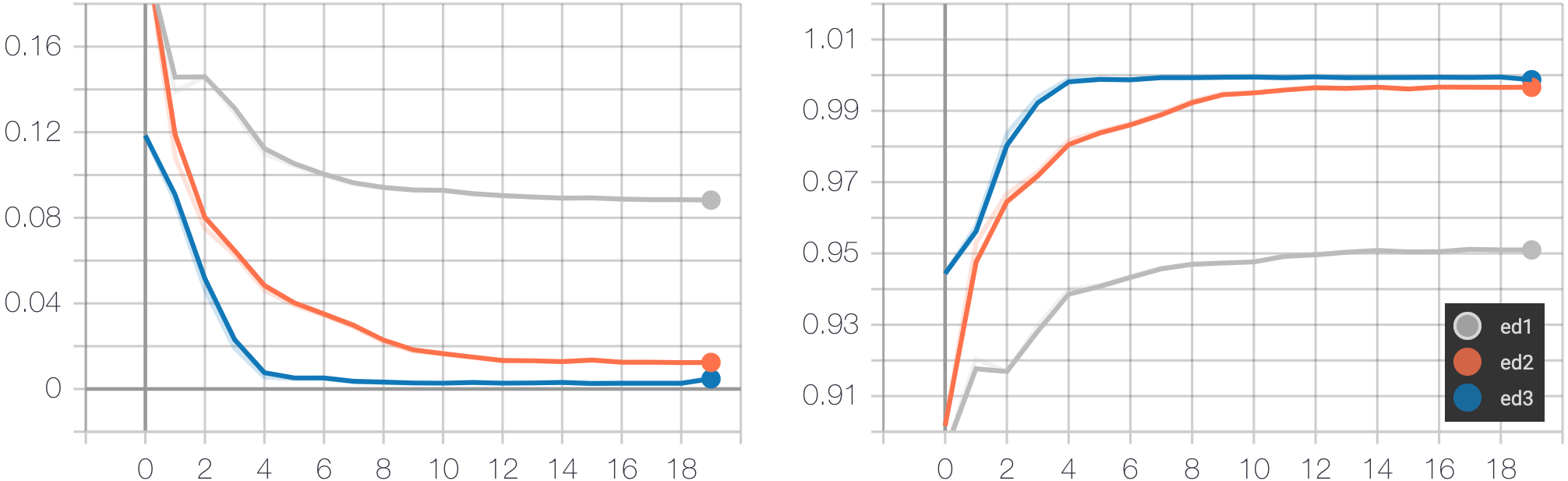
The three models (ED-1, ED-2, ED-3) are trained using ADAM-AMSGRAD optimization method for 100 epochs with learning rate 5e-4. The training task is to minimize the cross-entropy loss of predicting the next tokens of a program given the current tokens and a target image. We report the average loss and the average classification accuracy for predicted tokens in the figure below.
Automatic synthesizing HTML programs
| Datasets | pix2code | ED-1 | ED-2 | ED-3 |
|---|---|---|---|---|
| pix2code | 0.794 | 0.722 | 0.982 | 0.991 |
The above table reports the accuracy of predicted programs of the baseline method (pix2code) and the three proposed models when using beam search with a beam width of 3. Note that to evaluate pix2code, the output of pix2code is post-processed to convert from DSL to HTML. In addition, as pix2code only uses beam search without evaluating predicted programs, our methods also generate HTML programs using the same setting. The model with the highest accuracy is ED-3, which uses the attention mechanism. It outperforms pix2code significantly by 19.7%. Model ED-1 has the lowest accuracy (72.2%) despite having high test classification accuracy (95%). The reason is that the effect of the input image is faded away when the program is getting longer, and it is hard for the network to remember the image in the initial hidden state. Furthermore, as the average length of programs is very long (105 tokens), a minor change in a predicted token may lead to a final diverse program.
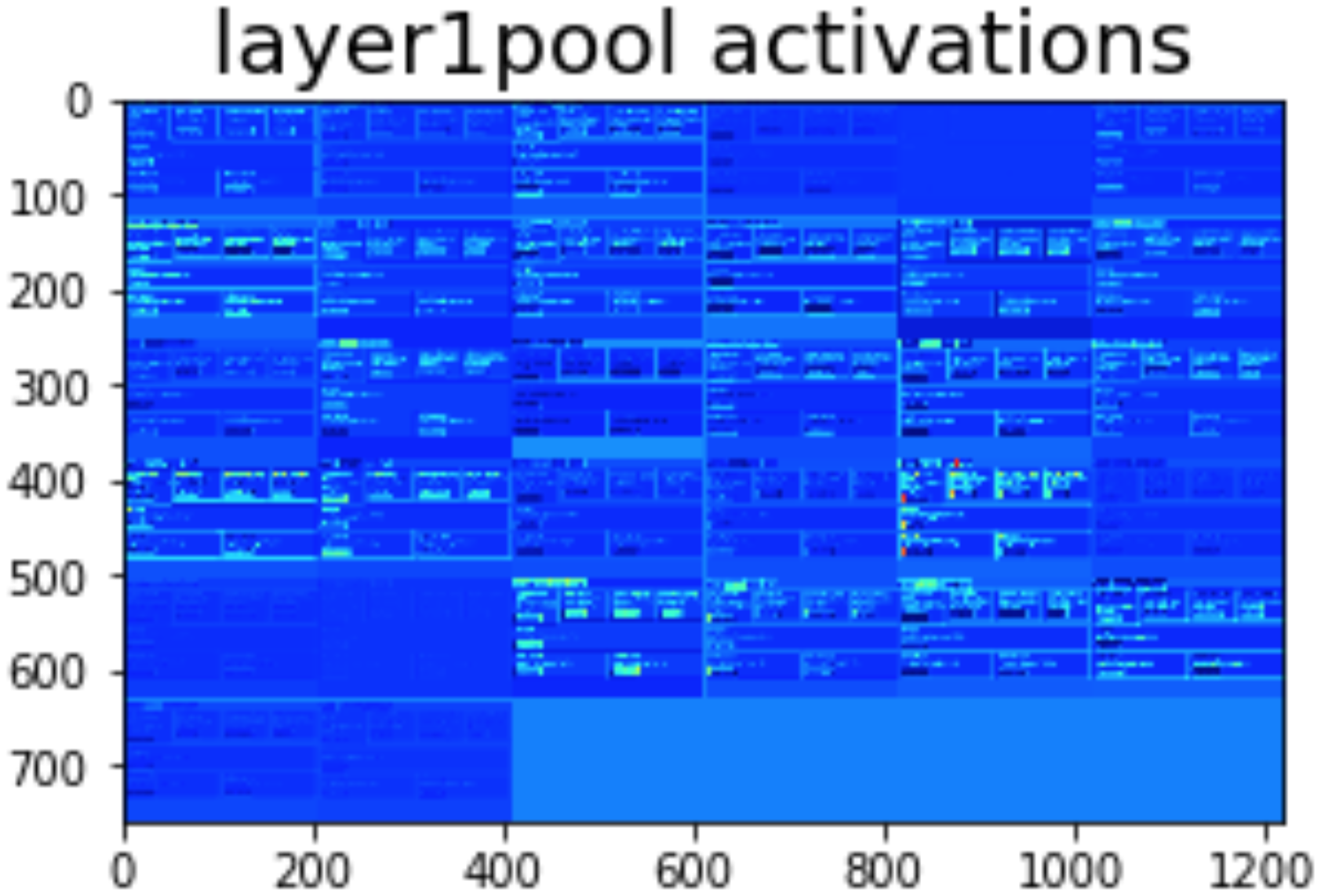
To further understand the results of the ED-3 model. We visualize the attention map to understand what information in the image \(I\) the model is used to make the prediction in Figure 8 below. In many cases, the model can focus on nearby locations, which are vital to predict the next token.
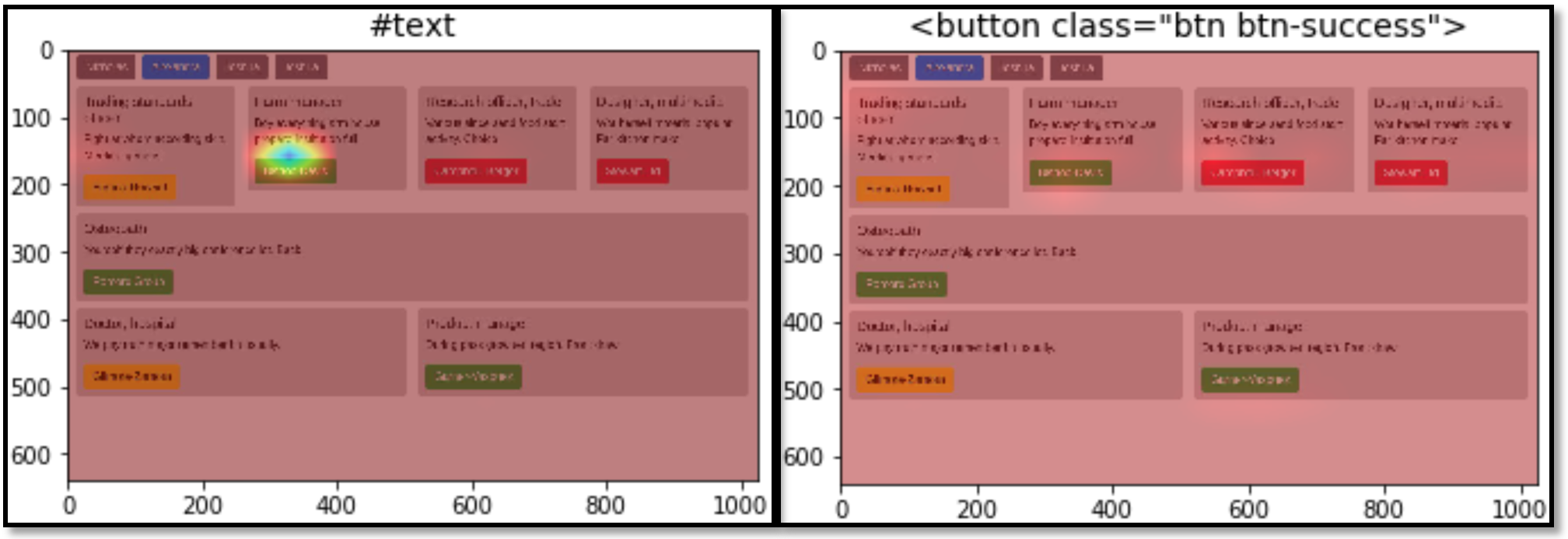
#text token. The model is able to focus to the nearby position in which the text belongs to. The image on the right shows attention map when predicting <button...> token. The model focuses (with low confidence) both on the green button (correct location) and the next red button (incorrect location).We also visualize the activation of different CNN layers to understand which features they can extract. Figure 9 is the activation of the first layer. In these activations, different filters are responsive to different components in a page such as buttons, text or headers.
Conclusion and Future Work
In this blog post, we have discussed how to synthesis HTML programs from screenshots of mock-up UIs using CNN-LSTM with the soft attention mechanism. The evaluation shows that our approach outperforms the current state-of-the-art by 19.7%.
One future direction of this work is to exploit available training data of websites on the Web. Also, generating an HTML program from a whole mock-up UI at once may be costly and inefficient as the program can get very long. To address this issue, we can partition the mock-up UI to different components, generates each HTML program for each component and combines to get back the final UI.
Another direction for future work is to integrate our system as a part of a pipeline that generates HTML program from hand-drawn images. In particular, we first reconstruct the mock-up UI from the hand-drawn image, then apply the system to synthesize the HTML program.
References
-
Beltramelli, Tony. “Pix2code: Generating Code from a Graphical User Interface Screenshot.” Proceedings of the ACM SIGCHI Symposium on Engineering Interactive Computing Systems, 2018, p. 3.
-
Xu, Kelvin, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhudinov, Rich Zemel, and Yoshua Bengio. “Show, attend and tell: Neural image caption generation with visual attention.” In International conference on machine learning, pp. 2048-2057. 2015.
Appendix
Reinforcement Learning Approach
Problem formulation
The problem of synthesizing HTML programs from GUI images can be formulated to RL as follows. Let the state of the environment be the current HTML program. The beginning state is the empty program, and the goal state is the target program. At each time step, the agent can take one of the following actions: creating a new HTML tag, adding new CSS class to the current tag, or closing an HTML tag. The reward for each action is the incremental improvement between the next program and the current program, which is calculated based on the GUI images of the next program and the current program, and the target GUI image. For example, if the similarity between the current program and the desired GUI is 0.7, and the similarity between the next program and the desired GUI is 0.8, then the reward for the action is 0.1.
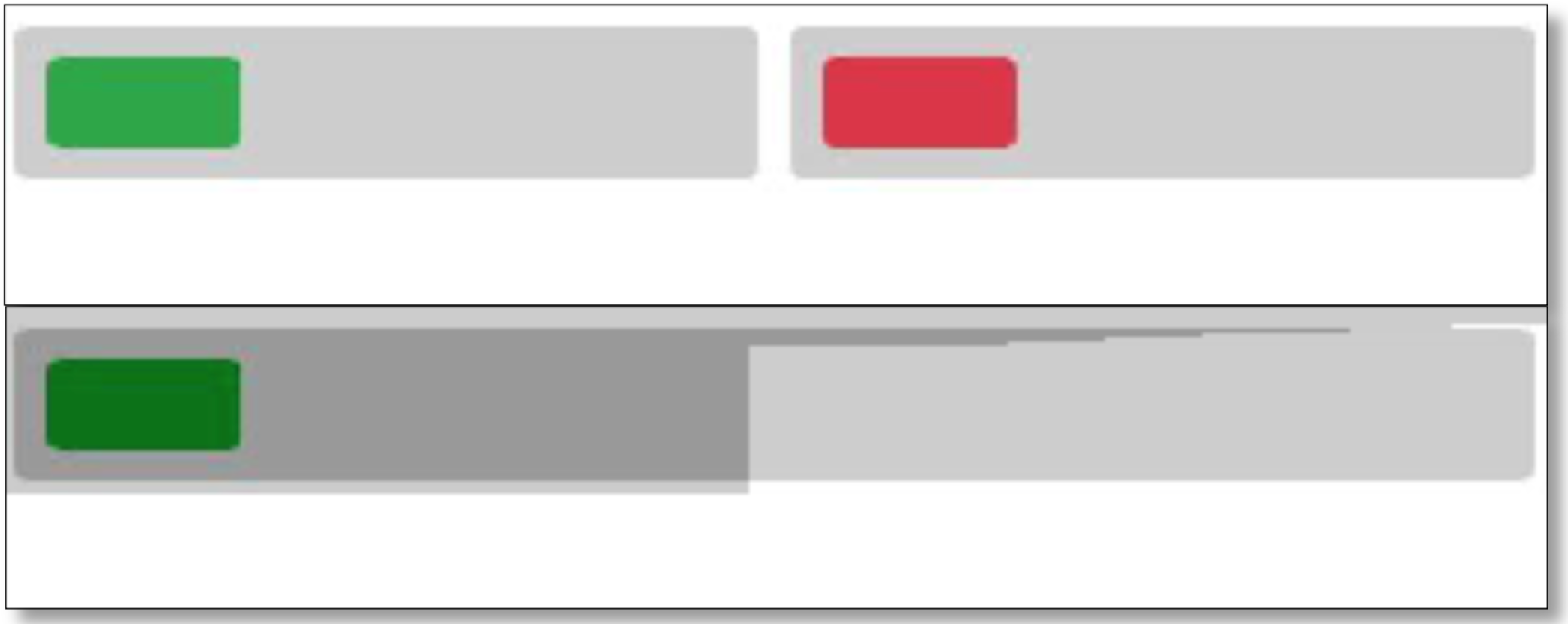
The similarity between the current program and the desired GUI is \(\alpha * \frac{\text{number of matched pixels}}{\text{total pixels of the image}}\), in which \(\alpha\) is a constant to prevent the scenario in which the similarity value is too small. The number of matched pixels is calculated by scanning from top to bottom and left to right. This scanning strategy mimics the way browser rendering visual HTML components and helps penalty errors related to the grid structured of the pages. Figure 10 below shows how we calculate the matched pixels.
To train an agent to know which action to take, we use a Deep Q-network (DQN) to estimate the Q-value function. We reuse the architecture of model ED-3 for DQN. To stabilize the training, we use a buffer to store the experience memories for training, and two separated DQN network, one for chosing action and one target network to generate target Q-value for that action.
Preliminary results
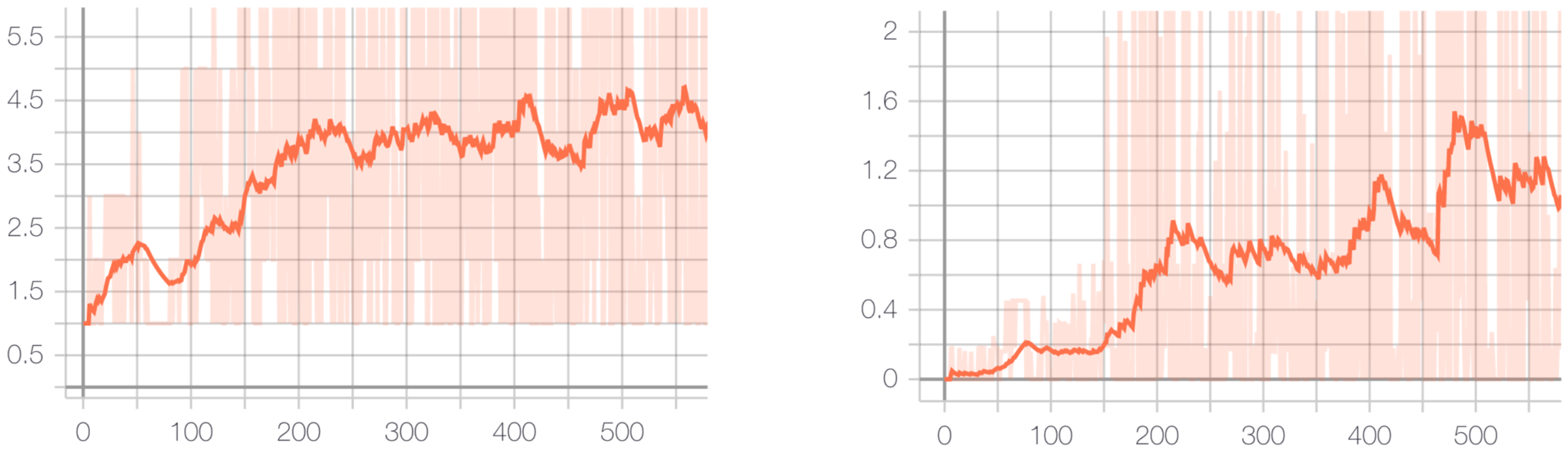
As the number of actions and the problem space is enormous (> 12 actions and ~12^105 possible settings), training a DQN takes a tremendous amount of time and resources. Within a limited time, we haven’t successfully trained and made RL work. During the training time, we observed that the accumulated reward and the length of episodes increase over time, which indicates that DQN may have learned something useful (Figure 11). The further direction for this approach could be pre-trained DQN and then applying RL.